Внутреннее представление и оптимизации строк в JavaScript-движке V8
- 2023-08-08
- ru
- CC BY-SA 4.0
- habr
- read in english
С самого рождения JavaScript, в каком-то смысле, был, во многом, языком для манипулирования текстом — от веб-страничек в самом начале, до полноценных компиляторов сейчас. Неудивительно, что в современных JS-движках достаточно много сил уделено оптимизации внутреннего представления строк и операций над ними.
В этой статье я хочу рассмотреть, как могут быть представлены строки в движке V8. Попытаюсь продемонстрировать их эффект, обогнав C++ в очень честном бенчмарке. А также покажу, в каких случаях они могут, наоборот, привести к проблемам с производительностью, и что в таких случаях можно сделать.
#Инструменты для исследования
Для того, чтобы наглядно увидеть, какая реализация строк используется в каждый конкретный момент, будем использовать отладочные функции V8. Для этого достаточно запустить Node.js с параметром --allow-natives-syntax:
$ node --allow-natives-syntax
Welcome to Node.js v20.3.0.
Type ".help" for more information.
> %DebugPrint(123)
DebugPrint: Smi: 0x7b (123)
123Для строк эта функция печатает довольно много информации, поэтому я буду заменять на /* ... */ то, что не важно для рассмотрения.
#Какие в V8 есть строки?
Список внутренних реализаций строк можно найти в исходниках V8.
StringSeqStringSeqOneByteStringSeqTwoByteString
SlicedStringConsStringThinStringExternalStringExternalOneByteStringExternalTwoByteString
InternalizedStringSeqInternalizedStringSeqOneByteInternalizedStringSeqTwoByteInternalizedString
ConsInternalizedStringExternalInternalizedStringExternalOneByteInternalizedStringExternalTwoByteInternalizedString
Большая часть этого многообразия получается из комбинации нескольких основных признаков:
#OneByte и TwoByte
Стандарт определяет строки как последовательности 16-битных значений. Но зачастую хранить по 2 байта на символ бывает слишком расточительно. На практике, очень многие строки не выходят за рамки ASCII. Поэтому внутри V8 строки могут быть как одно-, так и двухбайтовыми.
К примеру, вот ASCII-строка. Обратите внимание на ее type:
> %DebugPrint("hello")
DebugPrint: 0x209affbb9309: [String] in OldSpace: #hello
0x30f098a80299: [Map] in ReadOnlySpace
- type: ONE_BYTE_INTERNALIZED_STRING_TYPE
/* ... */А вот строка с не-ASCII символами, представлена как двухбайтовая:
> %DebugPrint("привет")
DebugPrint: 0x1b10a9ba2291: [String] in OldSpace: u#\u043f\u0440\u0438\u0432\u0435\u0442
0x30f098a81e29: [Map] in ReadOnlySpace
- type: INTERNALIZED_STRING_TYPE
/* ... */#Internalized
Некоторые строки — в частности, все строковые литералы интернирутся — собираются движком в единый пул строк, вне кучи. При использовании одинаковых строковых литералов эти объекты переиспользуются. Такие строки имеют внутренний тпи Internalized:
> %DebugPrint("hello")
DebugPrint: 0x209affbb9309: [String] in OldSpace: #hello
0x30f098a80299: [Map] in ReadOnlySpace
- type: ONE_BYTE_INTERNALIZED_STRING_TYPE
/* ... */Если значение строки известно только в рантайме, то она, как правило, не будет интернироваться. Обратите внимание на отсутствие INTERNALIZED в ее type:
> var fs = require("fs")
> fs.writeFileSync("hello.txt", "hello", "utf8")
> var s = fs.readFileSync("hello.txt", "utf8")
> %DebugPrint(s)
DebugPrint: 0x2c6f46782469: [String]: "hello"
0xd2880ec0879: [Map] in ReadOnlySpace
- type: ONE_BYTE_STRING_TYPE
/* ... */Конечно, ничего не мешает движку интернировать эту строку позже. Один из простых способов — заставить движок прочитать ее как строковый литерал при помощи eval:
> var ss = eval('"' + s + '"')
undefined
> %DebugPrint(ss)
DebugPrint: 0x80160fa1809: [String] in OldSpace: #hello
0xd2880ec0299: [Map] in ReadOnlySpace
- type: ONE_BYTE_INTERNALIZED_STRING_TYPE
/* ... */#External
External-строки хранятся не на куче, а в отдельных областях памяти, специально для них выделенных. Как правило, это применяется для очень больших строк. Для примера, давайте запустим Node.js с очень маленьким размером кучи, но выделим для строки много памяти:
// test.js
// создаем строку размером в 16 МБ
var s = Buffer.alloc(16 * 2 ** 20, 65).toString("ascii");
console.log(s.length);Запустим c ограничением кучи в 8 МБ:
$ node --max-old-space-size=8 test.js
16777216#Sliced
Для экономии памяти и времени на копирование данных, операция взятия подстроки возвращает Sliced-строку. Это аналог string view из других языков — то есть, просто указатель на строку-родителя, смещение и длина.
> var s = Buffer.alloc(256, 65).toString('ascii')
undefined
> %DebugPrint(s.slice(0, 15))
DebugPrint: 0x80e9bea9851: [String]: "AAAAAAAAAAAAAAA"
0xd2880ec1d09: [Map] in ReadOnlySpace
- type: SLICED_ONE_BYTE_STRING_TYPE
/* ... */Но если подстрока достаточно короткая, то выгоднее все-таки ее скопировать:
> %DebugPrint(s.slice(0, 5))
DebugPrint: 0x18a9c2e10169: [String]: "AAAAA"
0xd2880ec0879: [Map] in ReadOnlySpace
- type: ONE_BYTE_STRING_TYPE
/* ... */#Cons
Аналогично, операция конкатенации возвращает Cons-строку, содержащую только ссылки на левую и правую исходные строки:
> %DebugPrint(s + s)
DebugPrint: 0x2c6f467b3e09: [String]: c"AAAAAAAAAA/* ... */AA"
0xd2880ec1be9: [Map] in ReadOnlySpace
- type: CONS_ONE_BYTE_STRING_TYPEПри этом, опять-таки, для коротких строк это не применяется:
> %DebugPrint(s.slice(0, 2) + s.slice(0, 3))
DebugPrint: 0xec9b3412501: [String]: "AAAAA"
0xd2880ec0879: [Map] in ReadOnlySpace
- type: ONE_BYTE_STRING_TYPE
/* ... */#Преимущества оптимизаций: "обгоняем" C++
Итак, мы разобрались с тем, как именно представлены строки в V8. Давайте применим это на практике в одной из моих любимых дисциплин: нечестных сравнениях разных языков!
Правила просты: нам нужно придумать такую задачу, в которой JS-код окажется быстрее, чем строчка-в-строчку аналогичный код на C++. К примеру, давайте эксплуатировать то, что Cons-строки дают нам очень быструю конкатенацию, а Sliced-строки — очень быстрое взятие подстроки.
// unethical-benchmark.js
// дана строка text длиной 1500
// найти суммарную длину тех её подстрок, у которых длина больше 200
let text = "a".repeat(1500);
let result = "";
for (let i = 0; i < text.length; i++) {
for (let j = i + 201; j < text.length; j++) {
result += text.substr(i, j - i);
}
}
console.log(result.length);Для пущей честности запустим на голом V8, скачав его при помощи jsvu:
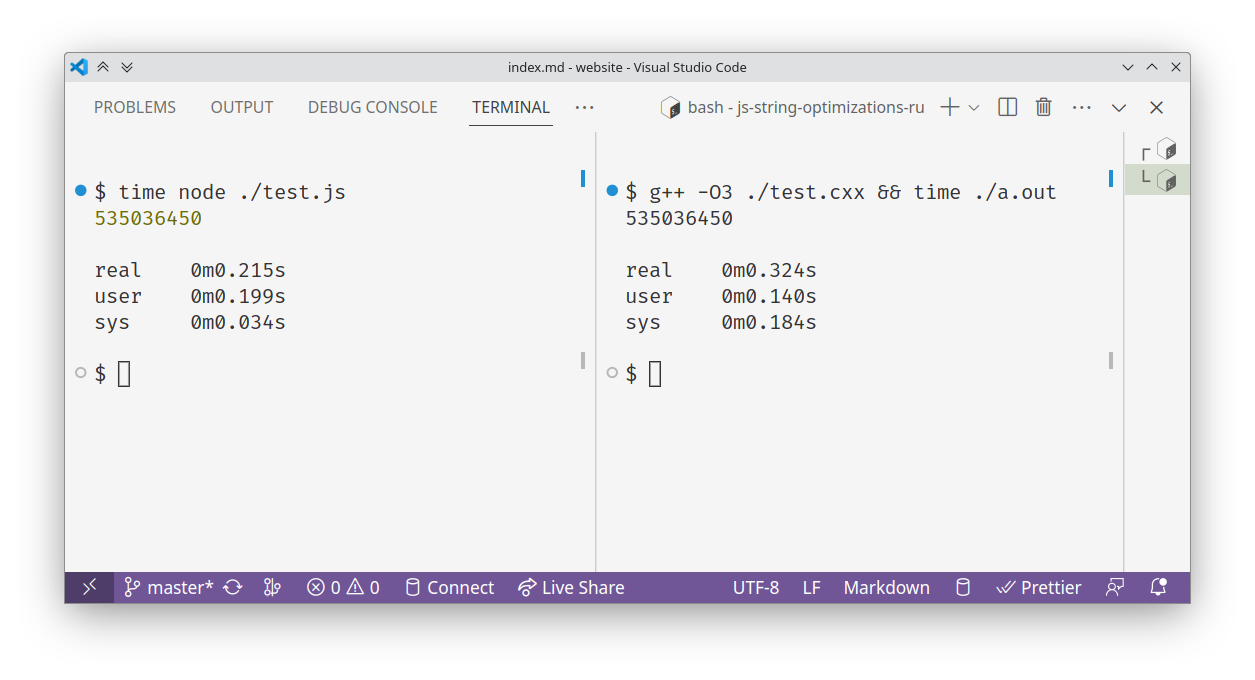
$ time ~/.jsvu/bin/v8 unethical-benchmark.js
535036450
real 0m0.145s
user 0m0.122s
sys 0m0.028sА теперь аналогичный строка-в-строку код на C++:
// unethical-benchmark.cxx
// дана строка text длиной 1500
// найти суммарную длину тех её подстрок, у которых длина больше 200
#include <iostream>
#include <string>
int main() {
std::string text(1500, 'a');
std::string result;
for (int i = 0; i < text.length(); i++) {
for (int j = i + 201; j < text.length(); j++) {
result += text.substr(i, j - i);
}
}
std::cout << result.length() << std::endl;
}$ g++ -O3 unethical-benchmark.cxx && time ./a.out
535036450
real 0m0.324s
user 0m0.176s
sys 0m0.147sРазумеется, это отвратительный код и отвратительное сравнение. Однако на нем хорошо виден именно эффект от Cons- и Sliced-строк. А именно: максимально наивный код, без всяких оптимизаций, может получить значительное ускорение.
#Недостатки оптимизаций: учимся "отмывать" строки
Недостаток таких оптимизаций в том, что ими довольно трудно управлять. В других языках программист может явно указать, где ему нужет string view, где string builder, а где однобайтовые строки — но в JS приходится либо терпеть умолчания движка, либо заниматься колдунством.
Для примера, давайте напишем небольшой скрипт, который вытащит нам все адреса ссылок из пары страниц комментов Хабра:
// urls-1.js
async function main() {
let pageUrls = [
"https://habr.com/ru/companies/ruvds/articles/346442/comments/",
"https://habr.com/ru/articles/203048/comments/",
];
let linkUrls = [];
for (let pageUrl of pageUrls) {
let html = await (await fetch(pageUrl)).text();
for (let match of html.matchAll(/href="(.*?)"/g)) {
let linkUrl = match[1];
linkUrls.push(linkUrl);
}
}
for (let linkUrl of linkUrls) {
console.log(linkUrl);
}
}
main();Посмотрим, с каким минимальным размером кучи получится его запустить:
$ node --max-old-space-size=10 urls-1.js > /dev/null # работает
$ node --max-old-space-size=9 urls-1.js > /dev/null
<--- Last few GCs --->
[252407:0x55b40628dbb0] 2894 ms: Mark-Compact 10.8 (13.7) -> 8.5 (16.9) MB, 9.22 / 0.00 ms (average mu = 0.989, current mu = 0.683) allocation failure; scavenge might not succeed
[252407:0x55b40628dbb0] 2906 ms: Mark-Compact (reduce) 9.7 (16.9) -> 9.1 (10.4) MB, 2.68 / 0.00 ms (+ 0.9 ms in 12 steps since start of marking, biggest step 0.1 ms, walltime since start of marking 10 ms) (average mu = 0.984, current mu = 0.681) fina
<--- JS stacktrace --->
FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out of memoryПолучается, ограничения в 10 МБ хватает, а вот при 9 МБ уже падает.
Давайте попробуем исправить. Из очевидных идей — в памяти всегда остается предыдущий html, даже когда он уже не нужен. Давайте занулим переменную, чтобы его утащила сборка мусора:
// urls-2.js
async function main() {
let pageUrls = [
"https://habr.com/ru/companies/ruvds/articles/346442/comments/",
"https://habr.com/ru/articles/203048/comments/",
];
let linkUrls = [];
for (let pageUrl of pageUrls) {
let html = await (await fetch(pageUrl)).text();
for (let match of html.matchAll(/href="(.*?)"/g)) {
let linkUrl = match[1];
linkUrls.push(linkUrl);
}
html = null; // <---
}
for (let linkUrl of linkUrls) {
console.log(linkUrl);
}
}
main();$ node --max-old-space-size=9 urls-2.js > /dev/null
<--- Last few GCs --->
[252792:0x5576c8da8bb0] 3078 ms: Mark-Compact 8.9 (12.3) -> 7.3 (12.3) MB, 6.65 / 0.02 ms (average mu = 0.997, current mu = 0.994) allocation failure; scavenge might not succeed
[252792:0x5576c8da8bb0] 3101 ms: Mark-Compact 10.7 (13.4) -> 8.5 (17.4) MB, 6.27 / 0.00 ms (average mu = 0.992, current mu = 0.725) allocation failure; scavenge might not succeed
<--- JS stacktrace --->
FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out of memoryНе помогло! Причина, на самом деле, именно в особых представлениях строк: все urls — подстроки html, представленные как Sliced-строки; они хранят ссылку на исходный html, не давая ему собраться в мусор.
Давайте отмоем эти строки!
// urls-3.js
async function main() {
let pageUrls = [
"https://habr.com/ru/companies/ruvds/articles/346442/comments/",
"https://habr.com/ru/articles/203048/comments/",
];
let linkUrls = [];
for (let pageUrl of pageUrls) {
let html = await (await fetch(pageUrl)).text();
for (let match of html.matchAll(/href="(.*?)"/g)) {
let linkUrl = match[1];
linkUrl = JSON.parse(JSON.stringify(linkUrl)); // <---
linkUrls.push(linkUrl);
}
html = null;
}
for (let linkUrl of linkUrls) {
console.log(linkUrl);
}
}
main();Выглядит как магия. Работает ли?
$ node --max-old-space-size=9 urls-3.js > /dev/null
# работает!
$ node --max-old-space-size=8 urls-3.js > /dev/null
$ node --max-old-space-size=7 urls-3.js > /dev/null
<--- Last few GCs --->
[253130:0x5566636cdbb0] 1621 ms: Scavenge 6.0 (8.8) -> 4.8 (8.8) MB, 1.45 / 0.00 ms (average mu = 1.000, current mu = 1.000) task;
[253130:0x5566636cdbb0] 1631 ms: Mark-Compact 4.9 (8.8) -> 4.4 (9.0) MB, 5.01 / 0.00 ms (average mu = 0.997, current mu = 0.997) allocation failure; GC in old space requested
[253130:0x5566636cdbb0] 1642 ms: Mark-Compact 7.3 (11.8) -> 7.0 (11.8) MB, 1.94 / 0.00 ms (average mu = 0.996, current mu = 0.827) allocation failure; GC in old space requested
<--- JS stacktrace --->
FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out of memoryКак видно выше, код стал падать только при ограничении в 7 МБ — мы выиграли порядка 2 МБ!
Потребление памяти можно улучшить еще больше, если вспомнить про еще одну особенность представления строк — TwoByte и OneByte. Воспользуемся тем, что Хабр, как и почти все остальные, отдает свои страницы в кодировке UTF-8:
// urls-4.js
async function main() {
let pageUrls = [
"https://habr.com/ru/companies/ruvds/articles/346442/comments/",
"https://habr.com/ru/articles/203048/comments/",
];
let linkUrls = [];
for (let pageUrl of pageUrls) {
let html = await (await fetch(pageUrl)).arrayBuffer(); // <---
html = Buffer.from(html).toString("ascii"); // <---
// наша регулярка прекрасно сработает
// на уровне отдельных байтов UTF-8
for (let match of html.matchAll(/href="(.*?)"/g)) {
let linkUrl = match[1];
// на случай, если в адресах были не-ASCII символы
linkUrl = Buffer.from(linkUrl, "ascii").toString("utf-8");
linkUrls.push(linkUrl);
}
html = null;
}
for (let linkUrl of linkUrls) {
console.log(linkUrl);
}
}
main();Выиграли еще около 1 МБ:
$ node --max-old-space-size=7 urls-4.js > /dev/null
# работает!
$ node --max-old-space-size=6 urls-4.js > /dev/null
<--- Last few GCs --->
[253789:0x563785444bb0] 1749 ms: Mark-Compact 4.9 (9.3) -> 4.4 (9.5) MB, 2.12 / 0.00 ms (average mu = 0.996, current mu = 0.831) allocation failure; GC in old space requested
[253789:0x563785444bb0] 2530 ms: Mark-Compact 7.5 (10.1) -> 5.5 (10.3) MB, 5.66 / 0.01 ms (average mu = 0.994, current mu = 0.993) allocation failure; scavenge might not succeed
<--- JS stacktrace --->
FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out of memory#Что в итоге?
Движок V8, как и другие современные среды исполнения JavaScript, включает множество оптимизаций для разных сценариев работы. Сегодня мы рассмотрели его внутреннее устройство строк. Намеренно эксплуатировать их, скорее всего, не получится — хоть мы и "обогнали" C++ на нашем нечестном бенчмарке. Но, с другой стороны, знание внутренностей строк может помочь отловить совершенно неожиданные проблемы с производительностью кода.